Правильная постановка вопроса должна быть такой: как натренировать сою собственную нейросеть? Писать сеть самому не нужно, нужно взять какую-то из готовых реализаций, которых есть множество, предыдущие авторы давали ссылки. Но сама по себе эта реализация подобна компьютеру, в который не закачали никаких программ. Для того, чтобы сеть решала вашу задачу, ее нужно научить.
И тут возникает собственно самое важное, что вам для этого потребуется: ДАННЫЕ. Много примеров задач, которые будут подаваться на вход нейросети, и правильные ответы на эти задачи. Нейросеть будет на этом учиться самостоятельно давать эти правильные ответы.
И вот тут возникает куча деталей и нюансов, которые нужно знать и понимать, чтобы это все имело шанс дать приемлемый результат. Осветить их все здесь нереально, поэтому просто перечислю некоторые пункты. Во-первых, объем данных. Это очень важный момент. Крупные компании, деятельность которых связана с машинным обучением, обычно содержат специальные отделы и штат сотрудников, занимающихся только сбором и обработкой данных для обучения нейросетей. Нередко данные приходится покупать, и вся эта деятельность выливается в заметную статью расходов. Во-вторых, представление данных. Если каждый объект в вашей задаче представлен относительно небольшим числом числовых параметров, то есть шанс, что их можно прямо в таком сыром виде дать нейросети, и получить приемлемый результат на выходе. Но если объекты сложные (картинки, звук, объекты переменной размерности), то скорее всего придется потратить время и силы на выделение из них содержательных для решаемой задачи признаков. Одно только это может занять очень много времени и иметь гораздо более влияние на итоговый результат, чем даже вид и архитектура выбранной для использования нейросети.
Нередки случаи, когда реальные данные оказываются слишком сырыми и непригодными для использования без предварительной обработки: содержат пропуски, шумы, противоречия и ошибки.
Данные должны быть собраны тоже не абы как, а грамотно и продуманно. Иначе обученная сеть может вести себя странно и даже решать совсем не ту задачу, которую предполагал автор.
Также нужно представлять себе, как грамотно организовать процесс обучения, чтобы сеть не оказалась переученной. Сложность сети нужно выбирать исходя из размерности данных и их количества. Часть данных нужно отложить для теста и при обучении не использовать, чтобы оценить реальное качество работы. Иногда различным объектам из обучающего множества нужно приписать различный вес. Иногда эти веса полезно варьировать в процессе обучения. Иногда полезно начинать обучение на части данных, а по мере обучения добавлять оставшиеся данные. В общем, это можно сравнить с кулинарией: у каждой хозяйки свои приемы готовки даже одинаковых блюд.
В последнее время все чаще и чаще говорят про так званные нейронные сети, дескать вскоре они будут активно применятся и в роботехнике, и в машиностроении, и во многих других сферах человеческой деятельности, ну а алгоритмы поисковых систем, того же Гугла уже потихоньку начинают на них работать. Что же представляют собой эти нейронные сети, как они работают, какое у них применение и чем они могут стать полезными для нас, обо всем этом читайте дальше.
Что такое нейронные сети
Нейронные сети – это одно из направлений научных исследований в области создания искусственного интеллекта (ИИ) в основе которого лежит стремление имитировать нервную систему человека. В том числе ее (нервной системы) способность исправлять ошибки и самообучаться. Все это, хотя и несколько грубо должно позволить смоделировать работу человеческого мозга.
Биологические нейронные сети
Но это определение абзацем выше чисто техническое, если же говорить языком биологии, то нейронная сеть представляет собой нервную систему человека, ту совокупность нейронов в нашем мозге, благодаря которым мы думаем, принимаем те или иные решения, воспринимаем мир вокруг нас.
Биологический нейрон – это специальная клетка, состоящая из ядра, тела и отростков, к тому же имеющая тесную связь с тысячами других нейронов. Через эту связь то и дело передаются электрохимические импульсы, приводящие всю нейронную сеть в состояние возбуждение или наоборот спокойствия. Например, какое-то приятное и одновременно волнующее событие (встреча любимого человека, победа в соревновании и т. д.) породит электрохимический импульс в нейронной сети, которая располагается в нашей голове, что приведет к ее возбуждению. Как следствие, нейронная сеть в нашем мозге свое возбуждение передаст и другим органам нашего тела и приведет к повышенному сердцебиению, более частому морганию глаз и т. д.
Тут на картинке приведена сильно упрощенная модель биологической нейронной сети мозга. Мы видим, что нейрон состоит из тела клетки и ядра, тело клетки, в свою очередь, имеет множество ответвленных волокон, названых дендритами. Длинные дендриты называются аксонами и имеют протяженность много большую, нежели показано на этом рисунке, посредством аксонов осуществляется связь между нейронами, благодаря ним и работает биологическая нейронная сеть в наших с вами головах.
История нейронных сетей
Какова же история развития нейронных сетей в науке и технике? Она берет свое начало с появлением первых компьютеров или ЭВМ (электронно-вычислительная машина) как их называли в те времена. Так еще в конце 1940-х годов некто Дональд Хебб разработал механизм нейронной сети, чем заложил правила обучения ЭВМ, этих «протокомпьютеров».
Дальнейшая хронология событий была следующей:
- В 1954 году происходит первое практическое использование нейронных сетей в работе ЭВМ.
- В 1958 году Франком Розенблатом разработан алгоритм распознавания образов и математическая аннотация к нему.
- В 1960-х годах интерес к разработке нейронных сетей несколько угас из-за слабых мощностей компьютеров того времени.
- И снова возродился уже в 1980-х годах, именно в этот период появляется система с механизмом обратной связи, разрабатываются алгоритмы самообучения.
- К 2000 году мощности компьютеров выросли настолько, что смогли воплотить самые смелые мечты ученых прошлого. В это время появляются программы распознавания голоса, компьютерного зрения и многое другое.

Искусственные нейронные сети
Под искусственными нейронными сетями принято понимать вычислительные системы, имеющие способности к самообучению, постепенному повышению своей производительности. Основными элементами структуры нейронной сети являются:
- Искусственные нейроны, представляющие собой элементарные, связанные между собой единицы.
- – это соединение, которые используется для отправки-получения информации между нейронами.
- Сигнал – собственно информация, подлежащая передаче.
Применение нейронных сетей
Область применения искусственных нейронных сетей с каждым годом все более расширяется, на сегодняшний день они используются в таких сферах как:
- Машинное обучение (machine learning), представляющее собой разновидность искусственного интеллекта. В основе его лежит обучение ИИ на примере миллионов однотипных задач. В наше время машинное обучение активно внедряют поисковые системы Гугл, Яндекс, Бинг, Байду. Так на основе миллионов поисковых запросов, которые все мы каждый день вводим в Гугле, их алгоритмы учатся показывать нам наиболее релевантную выдачу, чтобы мы могли найти именно то, что ищем.
- В роботехнике нейронные сети используются в выработке многочисленных алгоритмов для железных «мозгов» роботов.
- Архитекторы компьютерных систем пользуются нейронными сетями для решения проблемы параллельных вычислений.
- С помощью нейронных сетей математики могут разрешать разные сложные математические задачи.
Типы нейронных сетей
В целом для разных задач применяются различные виды и типы нейронных сетей, среди которых можно выделить:
- сверточные нейронные сети,
- реккурентные нейронные сети,
- нейронную сеть Хопфилда.

Сверточные нейронные сети
Сверточные сети являются одними из самых популярных типов искусственных нейронных сетей. Так они доказали свою эффективность в распознавании визуальных образов (видео и изображения), рекомендательных системах и обработке языка.
- Сверточные нейронные сети отлично масштабируются и могут использоваться для распознавания образов, какого угодно большого разрешения.
- В этих сетях используются объемные трехмерные нейроны. Внутри одного слоя нейроны связаны лишь небольшим полем, названые рецептивным слоем.
- Нейроны соседних слоев связаны посредством механизма пространственной локализации. Работу множества таких слоев обеспечивают особые нелинейные фильтры, реагирующие на все большее число пикселей.
Рекуррентные нейронные сети
Рекуррентными называют такие нейронные сети, соединения между нейронами которых, образуют ориентировочный цикл. Имеет такие характеристики:
- У каждого соединения есть свой вес, он же приоритет.
- Узлы делятся на два типа, вводные узлы и узлы скрытые.
- Информация в рекуррентной нейронной сети передается не только по прямой, слой за слоем, но и между самими нейронами.
- Важной отличительной особенностью рекуррентной нейронной сети является наличие так званой «области внимания», когда машине можно задать определенные фрагменты данных, требующие усиленной обработки.
Рекуррентные нейронные сети применяются в распознавании и обработке текстовых данных (в частотности на их основе работает Гугл переводчик, алгоритм Яндекс «Палех», голосовой помощник Apple Siri).
Нейронные сети, видео
И в завершение интересное видео о нейронных сетях.

При написании статьи старался сделать ее максимально интересной, полезной и качественной. Буду благодарен за любую обратную связь и конструктивную критику в виде комментариев к статье. Также Ваше пожелание/вопрос/предложение можете написать на мою почту [email protected] или в Фейсбук, с уважением автор.
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.

Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.

Обучение нейросетей происходит в два этапа:
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
 Прямое распространение
Прямое распространение
Зададим начальные веса случайным образом:
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
- y_ = fn(h1 , h2, h3)
Обратное распространение

- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.
 Популярный мем о том, как Карлсон стал Data Science разработчиком
Популярный мем о том, как Карлсон стал Data Science разработчиком
 Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль. Что при этом ускоряется/замедляется? Производные скорости.
Разберем необходимость частных производных на примере.
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:

Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:

Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:

Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения (learning rate)
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:

С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:

Функция активации (activation function)
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:

Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь измеряет «насколько хороша» нейронная сеть в отношении данной обучающей выборки и ожидаемых ответов. Она также может зависеть от таких переменных, как веса и смещения.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака - Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:

Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
 Популярные алгоритмы нейронных сетей (http://www.asimovinstitute.org/neural-network-zoo)
Популярные алгоритмы нейронных сетей (http://www.asimovinstitute.org/neural-network-zoo)
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Пример
Рассмотрим однослойную нейронную сеть:

Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:

Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.

Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Пример:
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Главное — баланс
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятье размерности
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
Компромисс
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
Действительно,

алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.
Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, . Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры нейронной сети.
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Что такое нейронная сеть?
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
Нейронные сети состоят из следующих компонентов:
- входной слой, x
- произвольное количество скрытых слоев
- выходной слой, ŷ
- набор весов и смещений между каждым слоем W и b
- выбор функции активации для каждого скрытого слоя σ ; в этой работе мы будем использовать функцию активации Sigmoid
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Обучение нейронной сети
Выход ŷ простой двухслойной нейронной сети:
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как обучение нейронной сети.
Каждая итерация обучающего процесса состоит из следующих шагов
- вычисление прогнозируемого выхода ŷ, называемого прямым распространением
- обновление весов и смещений, называемых обратным распространением
Последовательный график ниже иллюстрирует процесс:

Прямое распространение
Как мы видели на графике выше, прямое распространение - это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Функция потери
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок - это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения - найти набор весов и смещений, который минимизирует функцию потери.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции - это тангенс угла наклона функции.

Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется градиентным спуском .
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.
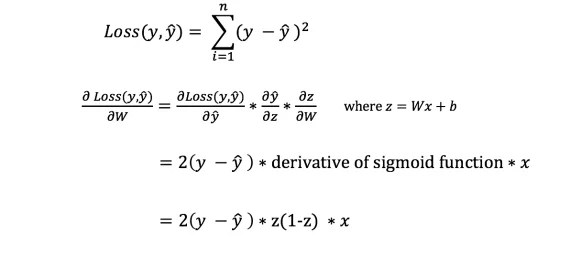
Фух! Это было громоздко, но позволило получить то, что нам нужно - производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Проверка работы нейросети
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весов
Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.

Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.

Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Финальные размышления
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!
Нейросети сейчас в моде, и не зря. С их помощью можно, к примеру, распознавать предметы на картинках или, наоборот, рисовать ночные кошмары Сальвадора Дали. Благодаря удобным библиотекам простейшие нейросети создаются всего парой строк кода, не больше уйдет и на обращение к искусственному интеллекту IBM.
Теория
Биологи до сих пор не знают, как именно работает мозг, но принцип действия отдельных элементов нервной системы неплохо изучен. Она состоит из нейронов - специализированных клеток, которые обмениваются между собой электрохимическими сигналами. У каждого нейрона имеется множество дендритов и один аксон. Дендриты можно сравнить со входами, через которые в нейрон поступают данные, аксон же служит его выходом. Соединения между дендритами и аксонами называют синапсами. Они не только передают сигналы, но и могут менять их амплитуду и частоту.
Преобразования, которые происходят на уровне отдельных нейронов, очень просты, однако даже совсем небольшие нейронные сети способны на многое. Все многообразие поведения червя Caenorhabditis elegans - движение, поиск пищи, различные реакции на внешние раздражители и многое другое - закодировано всего в трех сотнях нейронов. И ладно черви! Даже муравьям хватает 250 тысяч нейронов, а то, что они делают, машинам определенно не под силу.
Почти шестьдесят лет назад американский исследователь Фрэнк Розенблатт попытался создать компьютерную систему, устроенную по образу и подобию мозга, однако возможности его творения были крайне ограниченными. Интерес к нейросетям с тех пор вспыхивал неоднократно, однако раз за разом выяснялось, что вычислительной мощности не хватает на сколько-нибудь продвинутые нейросети. За последнее десятилетие в этом плане многое изменилось.
Электромеханический мозг с моторчиком

Машина Розенблатта называлась Mark I Perceptron. Она предназначалась для распознавания изображений - задачи, с которой компьютеры до сих пор справляются так себе. Mark I был снабжен подобием сетчатки глаза: квадратной матрицей из 400 фотоэлементов, двадцать по вертикали и двадцать по горизонтали. Фотоэлементы в случайном порядке подключались к электронным моделям нейронов, а они, в свою очередь, к восьми выходам. В качестве синапсов, соединяющих электронные нейроны, фотоэлементы и выходы, Розенблатт использовал потенциометры. При обучении перцептрона 512 шаговых двигателей автоматически вращали ручки потенциометров, регулируя напряжение на нейронах в зависимости от точности результата на выходе.
Вот в двух словах, как работает нейросеть. Искусственный нейрон, как и настоящий, имеет несколько входов и один выход. У каждого входа есть весовой коэффициент. Меняя эти коэффициенты, мы можем обучать нейронную сеть. Зависимость сигнала на выходе от сигналов на входе определяет так называемая функция активации.
В перцептроне Розенблатта функция активации складывала вес всех входов, на которые поступила логическая единица, а затем сравнивала результат с пороговым значением. Ее минус заключался в том, что незначительное изменение одного из весовых коэффициентов при таком подходе способно оказать несоразмерно большое влияние на результат. Это затрудняет обучение.
В современных нейронных сетях обычно используют нелинейные функции активации, например сигмоиду. К тому же у старых нейросетей было слишком мало слоев. Сейчас между входом и выходом обычно располагают один или несколько скрытых слоев нейронов. Именно там происходит все самое интересное.

Чтобы было проще понять, о чем идет речь, посмотри на эту схему. Это нейронная сеть прямого распространения с одним скрытым слоем. Каждый кружок соответствует нейрону. Слева находятся нейроны входного слоя. Справа - нейрон выходного слоя. В середине располагается скрытый слой с четырьмя нейронами. Выходы всех нейронов входного слоя подключены к каждому нейрону первого скрытого слоя. В свою очередь, входы нейрона выходного слоя связаны со всеми выходами нейронов скрытого слоя.
Не все нейронные сети устроены именно так. Например, существуют (хотя и менее распространены) сети, у которых сигнал с нейронов подается не только на следующий слой, как у сети прямого распространения с нашей схемы, но и в обратном направлении. Такие сети называются рекуррентными. Полностью соединенные слои - это тоже лишь один из вариантов, и одной из альтернатив мы даже коснемся.
Практика
Итак, давай попробуем построить простейшую нейронную сеть своими руками и разберемся в ее работе по ходу дела. Мы будем использовать Python с библиотекой Numpy (можно было бы обойтись и без Numpy, но с Numpy линейная алгебра отнимет меньше сил). Рассматриваемый пример основан на коде Эндрю Траска.
Нам понадобятся функции для вычисления сигмоиды и ее производной:
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «сайт», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», увеличит личную накопительную скидку и позволит накапливать профессиональный рейтинг Xakep Score!